


- Azure Machine Learning gives us a workbench to manage the end-to-end Machine Learning lifecycle that can be used by coding & non-coding data scientists
- Databricks gives us a scalable compute environment: if we want to run a big data machine learning job, it should run on Databricks
In this article, we will look at how Databricks can be used as a compute environment to run machine learning pipelines created with the Azure ML’s Python SDK. This topic is something that i found a little hard to follow within Azure ML documentation. By using a Databricks compute, big data can be efficiently processed in your ML projects. At the same time you can give access to business users to create , manage and run machine learning experiments without worrying about coding and focusing on the business need.
As the starting step we need to create a databricks workspace in the Azure portal and link this workspace to an Azure ML workspace. This is a very critical step as I struggled to link an excising ML workspace to a databricks workspace. The only thing that worked for me was to use the link function in the Azure databricks workspace home page. In the screenshot below I used a Databricks premium workspace.
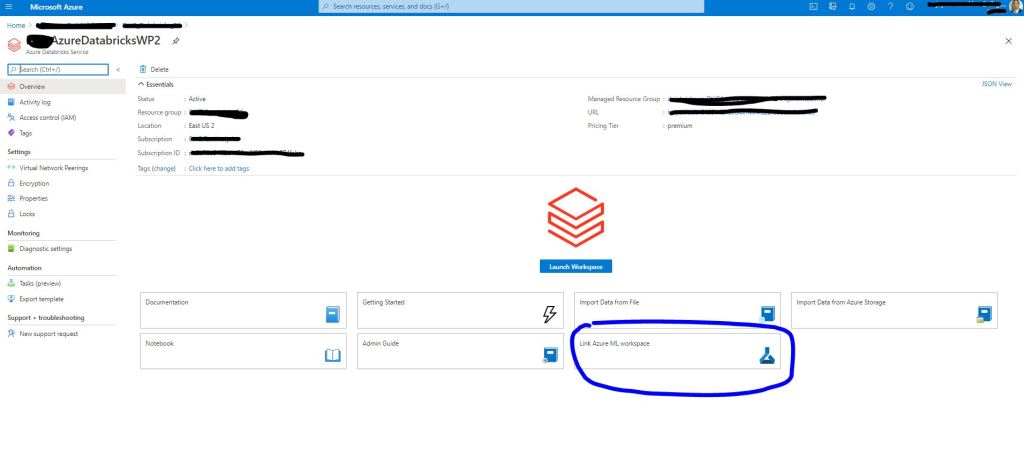
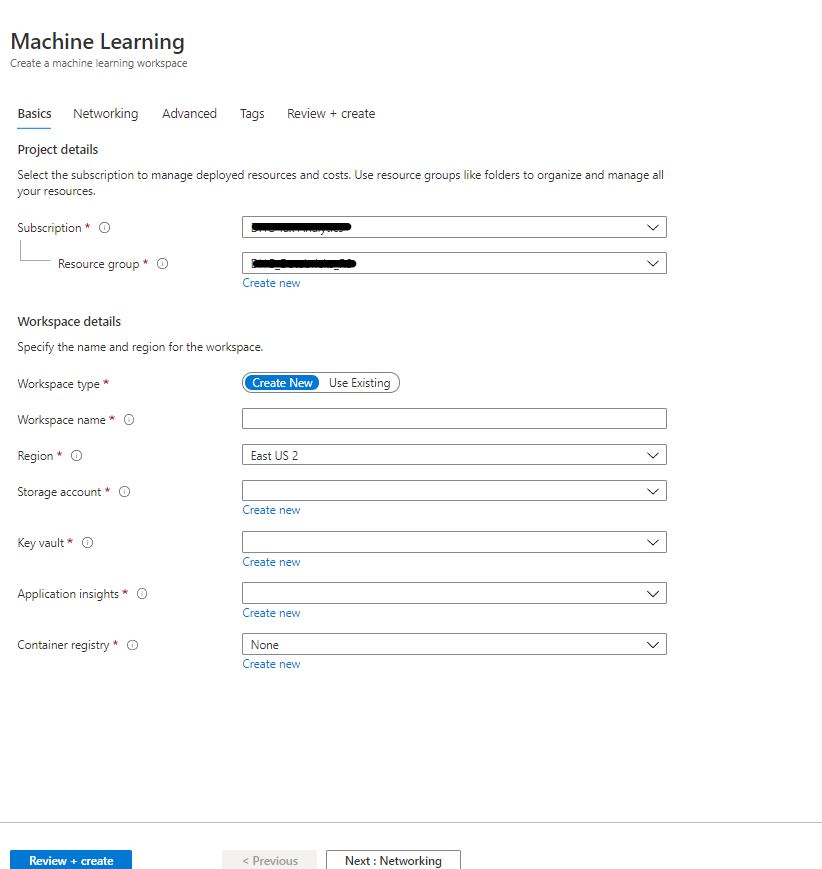
Once you click on “Link Azure ML workspace” you will see the screen shown below. Here make sure it is the same resource group and region as the databricks workspace.
Next we will create a cluster in the databricks workspace. The runtime I chose was 7.1(includes Apache Spark 3.0.0, Scala 2.12), Cluster Mode – Standard, Worker Type – Standard_D12_v2 28 GB , 4 cores, 1 DBU, Driver Type – Standard_D12_v2 28 GB , 4 cores, 1 DBU. Make sure this runtime is not ML
On this cluster install the azureml-sdk[databricks] library (Type PYPI)
Now create a new python notebook and attach it to the cluster created. Follow the code below to authenticate to the ML workspace.
%pip install –upgrade –force-reinstall -r https://aka.ms/automl_linux_requirements.txt
import azureml.core
print("SDK Version:", azureml.core.VERSION)
subscription_id = "your sub id" #you should be owner or contributor
resource_group = "azure ml workspace resource group name" #you should be owner or contributor
workspace_name = "azure ml workspace name" #your workspace name
workspace_region = "azure ml workspace region" #your region
from azureml.core import Workspace
from azureml.core.authentication import InteractiveLoginAuthentication
interactive_auth = InteractiveLoginAuthentication()
ws = Workspace.get(name=workspace_name,
subscription_id=subscription_id,
resource_group=resource_group)
ws.get_details()
Next I will show you how to create an auto ml experiment and deploy a model both in the Azure ML workspace and in Azure Databricks using python code.
